Dodge the Wicked Witch of ML Pipelines with TensorFlow Extended (TFX)
27 Apr 2020 - Darren Brien
Machine Learning pipelines give rise to challenges for the teams which build and maintain them. Changes to data over time can give rise to unexpected outcomes, which leads to bugs in places where you don’t find them in other software. Understanding your data and how it may change over time makes reasoning about machine learning pipelines easier. ML teams need additional tools to help keep their models up to date and predictions relevant, TFX is one such tool.
Even if the code hasn’t changed, the system behavior can because the data we use to train our models determines the predictions we make. If the data we are making predictions on today is different from the data we trained on, then all bets are off!
Let’s look at some common challenges when bringing ML to production and how TFX addresses them with a little help from Dorothy, Toto, and the Wizard of Oz!
When the data doesn’t match reality
“Lions? Tigers? and Bears? Oh my!”
Dorothy is navigating the yellow brick road through some dense forest, she wants to make it all the way to the Emerald City! She’s not too concerned about Lions, they’re pretty cowardly. Tigers and Bears are to be avoided.
With a solid 5G connection she can get her hands on a good amount of data and train a classifier to distinguish Lions from Tigers and Bears. We start with a corpus as below and hope to build our dataset over time.



Dorothy sends Toto ahead with a camera, as he encounters new animals along the way the model makes predictions. Overnight, when Scarecrow and the Tin Man are asleep, she retrains the model adding newly collected data. This way our classifier will improve, blending our original corpus with new data. The model’s performance (accuracy, loss, etc.) should be estimated from data which is representative of what we expect to see tomorrow, so Dorothy uses Toto’s pictures to evaluate the model.
Dorothy spots a problem, her corpus images are well-curated, high resolution, and landscape-oriented. Toto’s images aren’t so professional, and because the aspect ratio is different, she’ll have to make some changes to her model.

Toto’s images are portrait and aren’t as well-framed as our training images.
What is a machine learning pipeline?
“I’ll get you, my pretty, and your little dog too”
In the wild, ;), spotting these sorts of data issues can be tricky. Often we collect data over time, subtle changes (or drifts) in the distribution of features can cause issues to skip further down the yellow brick road.
One way Dorothy can spot something may be awry is to monitor the distribution of features in her corpus data (used for training) compared to the data Toto collects (used for inference). By keeping track of the aspect ratio of the images, Dorothy can monitor bias (or skew) in her pipeline. Dorothy’s problem is an example of Distribution Skew, the distribution of feature values in the training data are different from inference (or serving) data, possibly leading to poor quality predictions (there are other types of skew).
A machine learning pipeline encompasses more than training, it covers the entire data journey from storage through to inference and helps you track useful metrics about changes to the data and model over time.
How can Dorothy know her machine learning model has an issue? How can she judge when to update her model in production? How well should she expect her model to perform in the future?
How TensorFlow Extended can help
“The Wizard of Oz is one because of the wonderful things he does!”
TFX makes reasoning about your production machine learning pipeline easier. Helping you understand, validate, and monitor your data at scale. It has mechanisms to detect skew between your training and evaluation data as well as training and inference data. The architecture is scalable and ensures your process is repeatable and reproducible. Dorothy would like TFX!
Pipelines in TFX are built out of components, these are distinct steps that are responsible for one thing. Components are composed via the artifacts they exchange as inputs and outputs. Collections of components form a Directed Acyclic Graph (DAG) which describes a pipeline’s dependencies, they can be efficiently scheduled and executed on an orchestrator (more on these later).
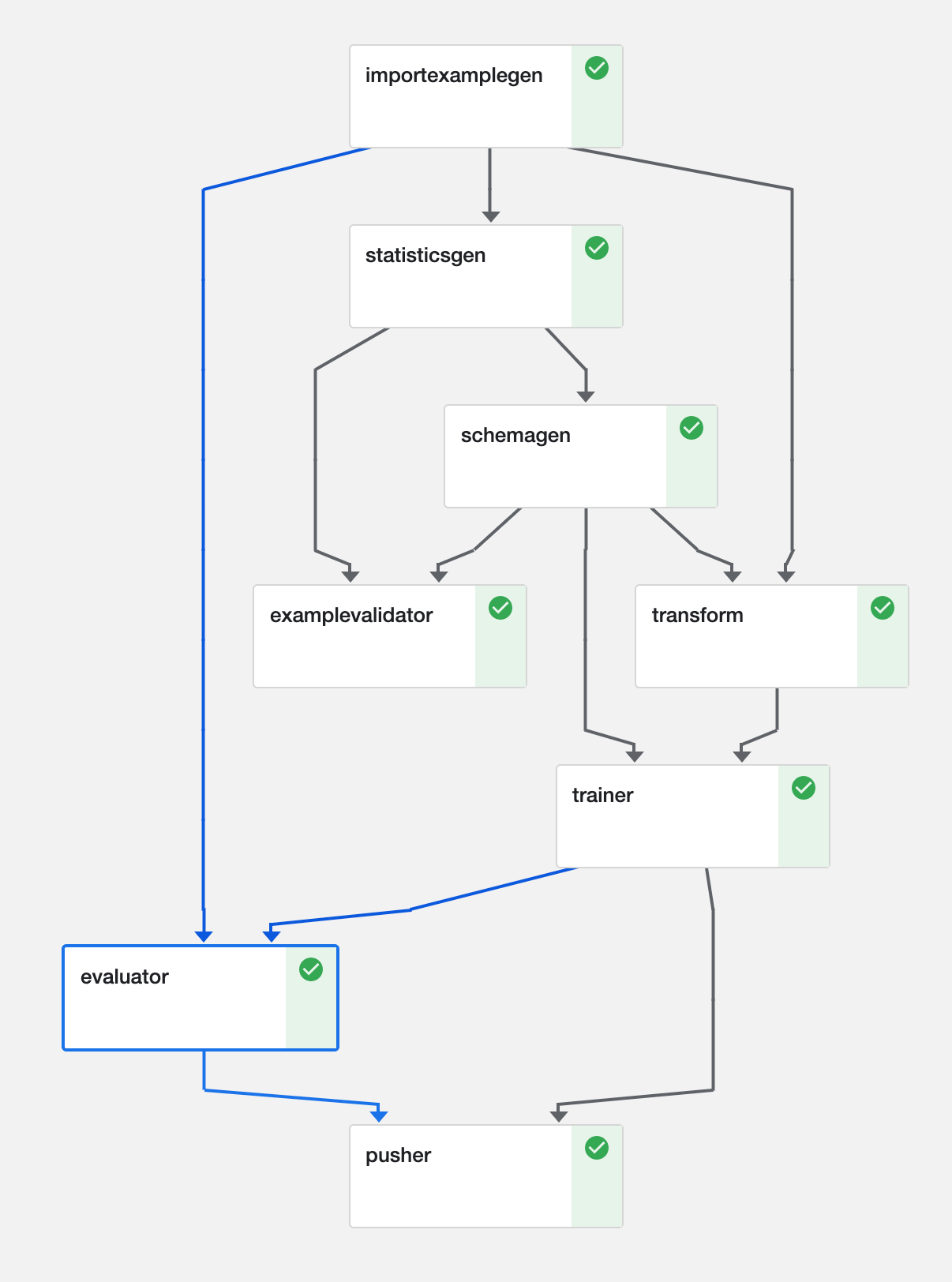 Example DAG for an image processing pipeline (Kubeflow)
Example DAG for an image processing pipeline (Kubeflow)
This is a classic pipeline, but developers can choose to work with only some of the following components because they are composable.
- Pipelines start with an ExampleGen, these components source data in its raw format from storage (disk/database). ExampleGens are coupled to your data format CSV, JSON, or TFRecords and they output training and evaluation sets. Subsequent components will use this raw data. ImportExampleGen can read TFRecords from cloud storage for example. If any of the example components isn’t enough for you, just implement your own.
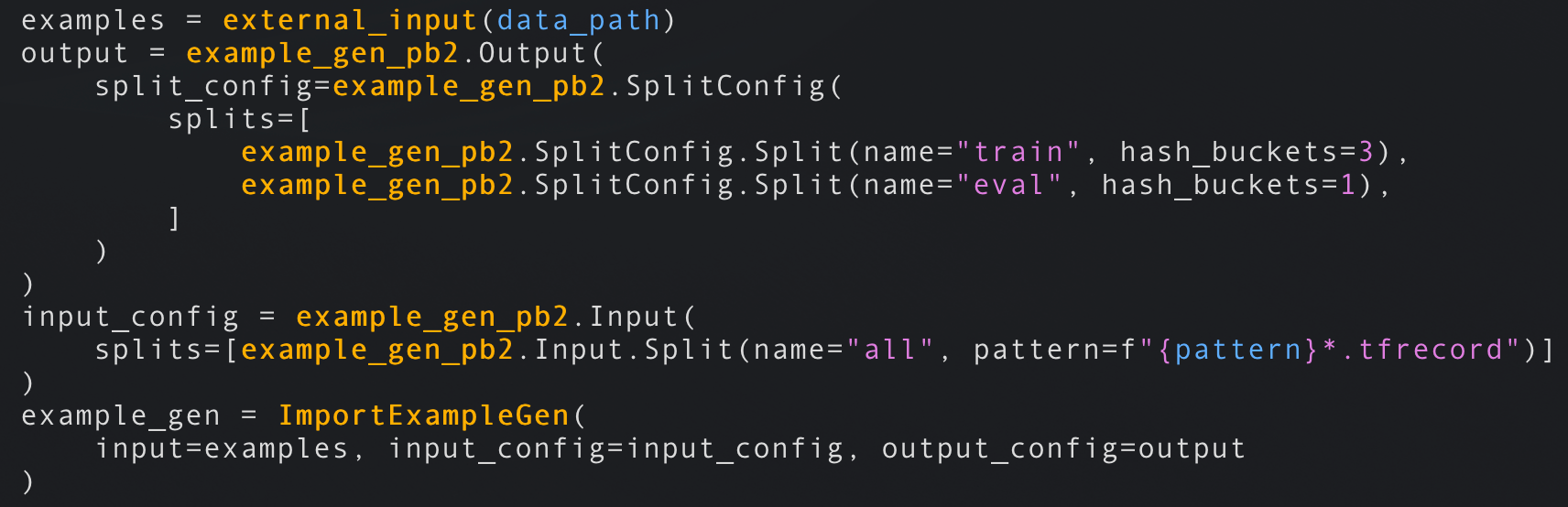 Read TFRecords from disk/cloud storage, split the training data 75%/25% train/eval
Read TFRecords from disk/cloud storage, split the training data 75%/25% train/eval
- StatisticsGen, SchemaGen, and Example Validator components work together and help you reason about our input data. StatisticsGen calculates feature statistics across the data. SchemaGen specifies the types and ranges the data can take, this can be automatically inferred, but specifying ranges manually can make errors easier to detect. ExampleValidator detects anomalous data using output from SchemaGen and StatisticsGen (see DAG above).
 Anomalies detected on some tabular data
Anomalies detected on some tabular data
-
The Transform component performs the feature engineering required to get the data into the correct format for the model to use during training and inference. By specifying the transform in the pipeline we ensure that there’s no possibility our training, evaluation, or serving code has any regressions. This avoids inadvertently training using features we don’t have available at inference time, Schema Skew.
-
Trainer takes our transformed data then trains and evaluates a model. Both Estimators and, more recently, Keras based models are supported. Models can be initialized from storage supporting warm start or transfer learning scenarios. Support for hyperparameter search has been released recently and is implemented using a Tuner component.
-
Evaluator and ResolverNode work in tandem to evaluate the model. The Evaluator component evaluates metrics we are interested in tracking our model against. ResolverNode provides a previous best model to run the evaluation set against, this ensures we compare old with new on a level playing field. If the newly trained model outperforms the existing one we “bless” the new model. Absolute performance metrics can also be specified, for example, accuracy must exceed 80%. These components prevent poor quality models making it into production. We can also evaluate metrics across slices of our data, ROC by an hour of the day for example, this gives us insight into where our model may be doing poorly and could be improved.
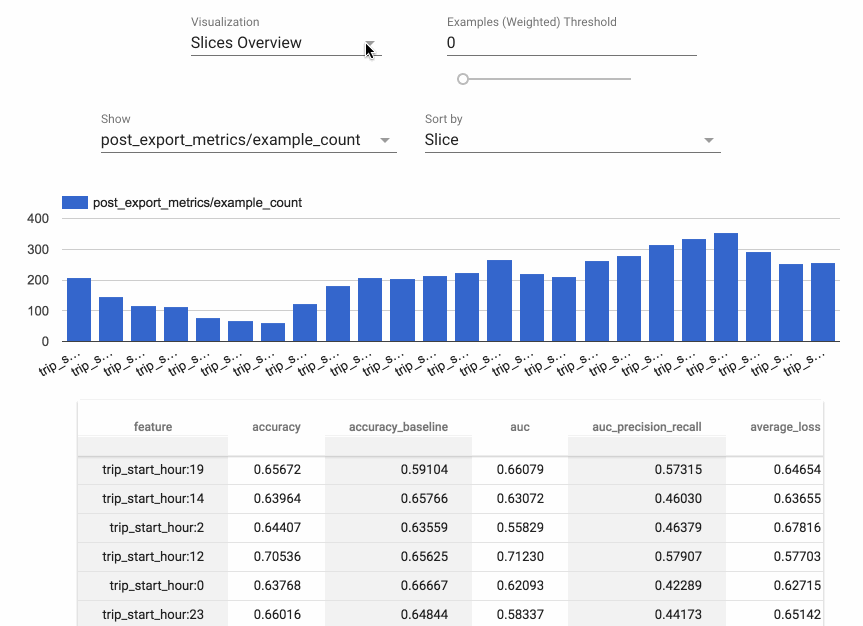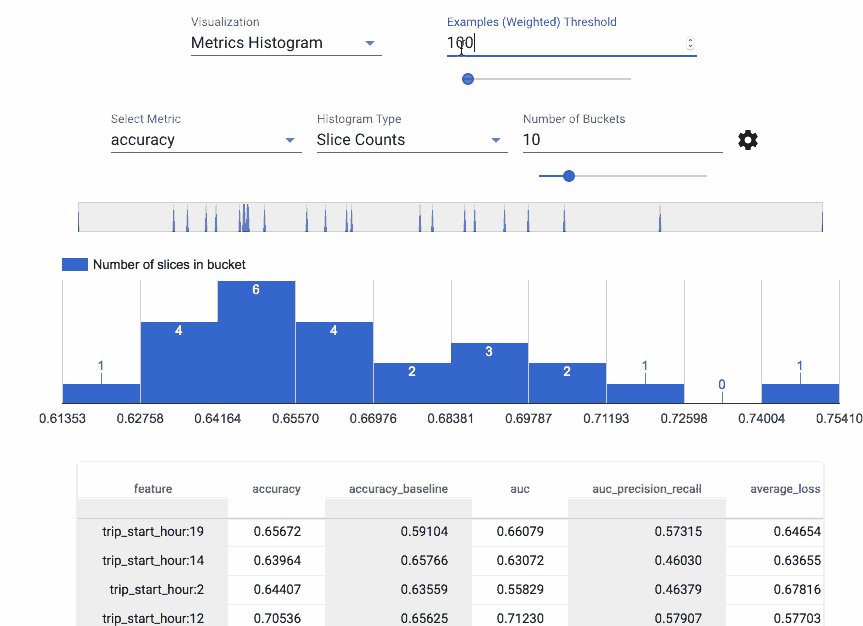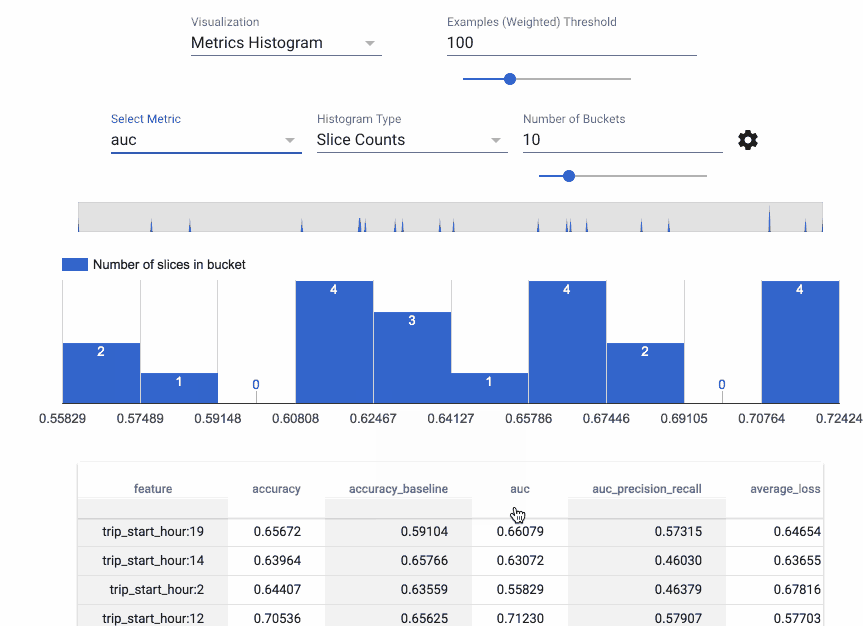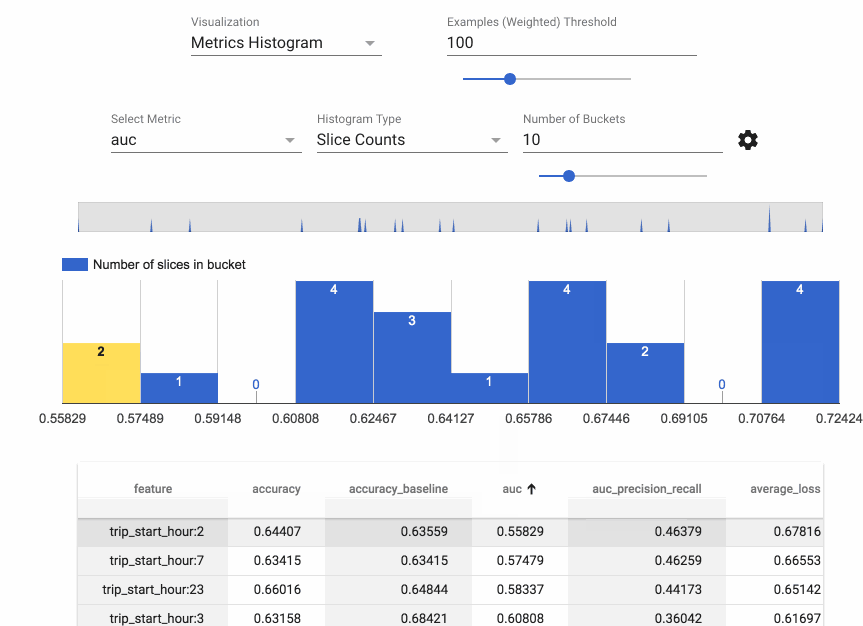 Evaluation metrics calculated by hour of day
Evaluation metrics calculated by hour of day
- Pusher persists our model to storage. If we’re using TensorFlowServing, this step can release our model to production. If you’re targeting mobile or the browser pusher also support TFLite and TF.js.
Which orchestrator should I use?
“Pay no attention to that man behind the curtain!”
TFX provides a higher level of abstraction when building ML pipelines. It’s designed to be portable which means you’re not locked into a single environment or orchestration framework. Furthermore, you can run it on-premise or on cloud platforms, it’s also conceivable for a pipeline to run in multiple cloud environments. This flexibility means you can pick the platform which best suits your needs.
A TFX DAG is executed on an Orchestrator, currently, TFX supports a few of these.
-
Kubeflow (AI Platform Pipelines on GCP) runs on Kubernetes, also ubiquitous in tech teams and production. Kubeflow is designed for running Machine Learning pipelines, it’s less mature than the other options and just reached stable status. If you are managing multiple models and want to be able to scale your cluster to meet your training needs it may be a good fit. Serving your model on Kubernetes is also a breeze!
-
Apache Beam (Cloud Dataflow on GCP) is great for processing datasets in parallel. TFX uses Beam for distributed data processing, and so other orchestrators use Beam too (including Beam itself when you use it as an orchestrator!). It can also be run locally and so is useful for debugging a pipeline using Direct Runner.
-
Airflow (Cloud Composer on GCP) is popular in Data Engineering teams, if you have an instance of this up and running already, running your pipeline here will be familiar with little additional infrastructure to manage.
The Trainer and Pusher components have executors that support these components being executed on the GCP AI platform to train and serve your model in a serverless environment.
Closing thoughts
“Toto, I’ve got a feeling we’re not in Kansas anymore.”

More teams than ever are responsible for managing Machine Learning pipelines in production. TFX helps manage some of the unique challenges ML teams face bringing their software to the production environment. TFX runs on a growing list of orchestrators, you may already have most of the infrastructure you need to get started using TFX today! Choosing the right orchestrator will allow your platform to grow with your data and support the experimentation necessary to build useful models.